“第一性原理”拆解计算机网络面试题
网络的全貌
我读过不少计算机网络方面的书,但也正是因为网络太复杂了,这些书一般都只讲其中的一个协议(比如 HTTP),或者是一个局部的技术(比如网络设备的部署)。但面试中的问题,往往不是孤立的。考官更可能从一个实际的场景出发,比如问:“从输入网址到显示出网页,这中间到底发生了什么?”如果我们只是熟悉TCP、IP、DNS这些分散的知识点,却说不清它们之间如何衔接、怎样协同工作,回答起来就容易显得零碎,甚至前后矛盾。
这其实指向了一个更根本的问题:我们学的许多网络技术,它们究竟为什么存在?又在整个通信过程中扮演什么角色?用户根勤先生的话说就是:不理解网络的全貌,也就无法理解每一种网络技术背后的本质意义。如果只是学习TCP/IP、以太网这些单独的技术,我们看到的可能只是一行行协议规范、一条条配置命令,却看不到它们所服务的整体目标,也就无法理解网络这个系统的全貌;如果无法理解网络的全貌,也就无法理解每一种网络技术背后的本质意义;而如果无法理解其本质意义,学习就只能停留在死记硬背的阶段,很难在面试或实际工作中灵活运用。
因此,在接下来的内容中,我将试着从一个完整的网络请求过程出发,把各个环节可能遇到的面试问题串联起来理解。我们就从在浏览器输入网址(比如 https://www.mcqueen95.cn )并按下回车开始,一步步追踪这个请求是如何被处理、封装、传输、最终又被组装和呈现的。通过这条连贯的线索,你不仅能看清楚每个协议出现在哪一阶段、承担什么功能,也会逐渐明白:网络设计中的许多选择,其实是在不同约束下做出的逻辑回应。
用这样的方式准备面试,或许比孤立背诵知识点要慢一些,但它能帮你建立起一种更稳固、也更清晰的理解框架——当被问到某个具体协议时,你能自然地把它放回通信流程中,解释它从何而来、为何在此、又去往何处。
那么,我们开始吧。
版权与参考声明
本文在撰写的过程中,深受两部优秀作品的启发:
一是户根勤先生的《网络是怎样连接的》。如果说传统教材教会了我网络的“规则”,那么这本书则为我勾勒出一幅完整的“地图”————从你在浏览器按下回车,到网页最终呈现,数据包的每一次传输、每一次过滤,都被描绘得清晰如画。作为一名初学者,它是通向网络世界最友好的入口。
二是小林coding网络面试题系列。文中涉及的具体题目与经典回答,多有参考于此。这些凝练的总结,为我梳理知识点提供了坚实的骨架。
站在巨人的肩膀上,才能望得远一些。我做的,仅仅是在他们搭建的清晰逻辑之上,尝试融入自己作为求职者的思考过程——即那种“抛开结论,追问起源”的第一性原理式推导。如果这篇文章能对你有一点帮助,那多要要归功于他们卓越的工作。
在此,向各位前辈与分享者,致以最诚挚的感谢。也祝各位读者朋友能从本文中有所收获。
第1章:浏览器生成消息——探索应用层的起点
本章核心:当你在地址栏按下回车,第一个真正意义上的网络行为是什么?
- URL 解析:一个网址如何被拆解成协议、主机名、端口、路径?这背后是统一的资源定位规则。
- HTTP 请求的诞生:浏览器如何根据你的动作(输入、刷新、点击)生成具有特定方法(GET/POST)、头部和目标的请求报文?这定义了本次通信的“意图”。
- DNS 查询的启动:如何将人类可读的域名(如 www.mcqueen95.cn )转换为机器寻址所需的 IP 地址?我们将探究本地缓存、递归查询与迭代查询的完整过程。
- Socket API 的调用:应用层如何向操作系统发出第一条指令,请求建立一个通往远方的连接?
面试题逻辑起点:本章将回答关于 HTTP 语义、URL 组成、DNS 解析原理及浏览器行为的第一性问题。
1.1.1 URL的结构,以及每一部分的实际意义?
当你输入 https://www.example.com:8080/path/to/page?name=value#section 时,浏览器面对的是一串符合特定规则的文本。这个规则,就是为了明确地告诉计算机:“我想用某种方法,从某个地方,取回某个东西。”
首先,开头的 https:// 是协议。它回答了“怎么去拿?”这个问题。就像寄信要选择平邮还是快递一样,http 和 https 决定了数据传送的基本规则和安全性。它之所以在最前面,是因为这个选择会影响后续所有步骤。
紧接着的 www.example.com 是主机名。它解决了“去哪里拿?”的问题。直接使用IP地址(比如 192.0.2.1)对计算机很友好,但对人来说太难记了。于是,我们在中间加了一层好记的名字,这就是域名。浏览器后面会通过DNS,把这个好记的名字翻译成机器认识的IP地址。
主机名后面有时会跟着 :8080,这是端口号。你可以把它想象成一个大楼里的房间号。服务器这台“大楼”(IP地址)可能同时提供很多服务:80号房间是网页服务,25号是邮件服务。端口号就是告诉服务器:“请把这份请求交给处理网页的那个程序。”如果省略了,浏览器就会用协议的默认端口(比如HTTPS是443)。
/path/to/page 是路径。它指向服务器上某个具体的资源位置,就像文件系统里的文件夹和文件路径,告诉我们最终想要的是“什么东西”。
?name=value 这部分是查询字符串。它的作用是把一些额外的、动态的要求传递给服务器。比如在搜索时,?q=keyword 就把关键词传了过去。多个参数可以用 & 连接起来。
最后的 #section 叫片段标识符,或者通俗点叫“锚点”。有趣的是,浏览器不会把这部分发给服务器。它的作用是等页面加载完成后,自动滚动到页面里某个特定的位置。所以,它纯粹是浏览器内部的一个“寻路标记”。
所以一个URL的构成,其实是一个层层递进的定位过程:先定方式(协议),再定地点(主机和端口),然后定目标(路径),最后附上具体要求(查询)和内部定位(锚点)。理解了这个结构,你就能明白浏览器在拿到一个URL后,第一件要做的事就是对URL进行解析,从而生成发送给 Web 服务器的请求消息。
1.1.2 当浏览器拿到一个URL后,它是怎么一步步准备并发出HTTP请求的?
首先,它会看协议。如果是 http 或 https,它就知道要动用HTTP这套规则来办事。如果是 ftp,那又是另一套程序。这就是分层设计的好处,上面决定做什么,下面负责具体执行。
然后,它要解决“门牌号”问题。主机名 www.example.com 对人友好,但网络世界只认IP地址。所以,浏览器会去查DNS,就像查电话本一样,把名字转换成数字地址。为了提高效率,浏览器会先看看自己的“通讯录”(本地缓存)里有没有记录,没有再一层层去问。
地址找到了,接下来要确定“找谁谈”。端口号就是用来指定服务器上具体负责接待的程序。如果URL里没写,浏览器就按惯例来:HTTP用80端口,HTTPS用443端口。
在这些基础信息都明确后,浏览器才开始构思这次通信的具体内容。它会把本次请求封装成一个结构化的HTTP请求报文。这个报文以一行请求行开始,里面包含了方法(比如GET表示获取,POST表示提交)、路径和HTTP版本。这就像一封信的开头,写明了你的意图。
紧接着是请求头,这是一系列“键值对”,用来告诉服务器更多关于这次请求和客户端自身的细节。比如:
- Host:
www.example.com:这在今天尤其重要,因为一台服务器可能托管了很多个网站,必须靠这个头来区分。 - User-Agent:大致说明“我是哪个浏览器,什么版本”,服务器有时会根据这个返回适配的页面。
- Accept:告诉服务器“我更喜欢接收哪种格式的数据”,比如是HTML还是JSON,是否支持压缩等。
- Content-Type:指定请求体(如果有)的媒体类型。这告诉服务器“我发送过来的数据是什么格式的”。
- Content-Length:以字节为单位,精确指定请求体的大小。这对于服务器至关重要,因为它告诉服务器“应该从TCP流中读取多少字节来获取完整的请求体”。
- 如果之前访问过,还会带上 Cookie,这样服务器就知道“哦,又是你来了”,维持了有状态的对话。
所有请求头(对于请求)或响应头(对于响应)的集合就是报文首部(Message Headers),它包括起始行和所有的头部字段。
1 | POST /api/users HTTP/1.1 ← 起始行(请求行) |
所有这些信息都准备好之后,HTTP请求报文就成形了。但请注意,到这一步,报文还只是待在浏览器的内存里,并没有发出去。它要等待一个至关重要的步骤:建立一条通往服务器的、可靠的传输通道。这就是TCP连接要做的事了,我们下一章再细说。
简单来说,从URL到发出请求,浏览器扮演了一个非常称职的“秘书”角色:它解析指令、查找地址、准备文件、填写表单,把所有前期工作都打理得井井有条,只等连接建立,就能把这份“公函”正式发送出去。
1.1.3 为什么需要对URL进行编码?哪些字符是必须被编码的?
URL编码,有时候你看地址栏里出现一堆%20、%E6这样的字符,可能会觉得有点乱。但这其实是为了解决一个很实际的问题:如何用一套有限的字符,安全、无歧义地表达所有信息。
URL在设计时,主要用的是英文字母、数字和少数几个符号(像 -, ., _, ~)。这些被称为“安全字符”。但现实世界的信息要丰富得多,比如中文、空格、各种标点符号,它们在URL里可能会“闯祸”。
举个例子,URL中的 / 是用来分隔路径的,? 和 # 用来标记查询和锚点的开始。如果你的查询参数里本身就含有一个 & 符号(它在URL里是用来分隔不同参数的),那就会产生混乱。计算机无法知道这个 & 是参数值的一部分,还是表示下一个参数开始了。
为了解决这个矛盾,人们想出了一个聪明又直接的办法:把所有“不安全”的、有特殊含义的字符,统统转换成 % 后面跟上两位十六进制数字的形式。比如:
- 空格,在URL里很容易引起解析问题,就编码成 %20(20是空格的ASCII码的十六进制)。
- 一个中文字“网”,它在UTF-8编码下占三个字节,就会被编码成 %E7%BD%91。
- 那个捣乱的 & 符号,在参数值里就得编码成 %26。
那么,哪些情况必须编码呢?主要是三类字符:
- 有特殊功能的保留字符:像 ?、#、/、&、= 等等。当它们需要作为参数值本身出现时,就必须编码。
- 非ASCII字符:所有不在标准ASCII表里的字符,比如中文、日文、表情符号。
- 某些不便于打印或传输的字符:比如空格。虽然在查询参数里空格有时可以用 + 代替,但在路径部分,它必须被编码成 %20。
所以,URL编码本质上是一套“转义”规则。它确保任何数据,哪怕是乱码或特殊符号,都能被安全地“塞进”URL这个标准格式的“信封”里进行传递,不会和信封本身的格式记号产生冲突。浏览器在发送请求前,会自动帮我们做好这件事;而在服务器端,接收程序会反向解码,还原出原始信息。
1.1.4 相对URL和绝对URL有什么区别?浏览器怎么处理页面中的相对URL?
想象一下,你要告诉朋友一本书的位置。你可以说“它在市图书馆三楼科学阅览室B排书架”(这像绝对URL),也可以说“从你现在坐的桌子往前走,左手边第二个书架”(这就像相对URL)。在网页世界里,这两种指路方式也同时存在。
绝对URL非常完整,它包含了获取资源所需的全部信息:协议、主机、路径等。无论你在哪个页面,https://www.example.com/about.html 这个地址的含义都是确定无疑的。它的好处是准确、独立,但缺点是不够灵活。如果整个网站换了域名,所有使用绝对URL的链接都会失效。
而相对URL就灵活多了。它只指定从“当前位置”出发,如何到达目标。比如在 https://www.example.com/products/index.html 这个页面里,一个链接写成 ./detail.html。浏览器看到这个相对路径,就会以当前页面的地址为基础,进行“导航”:
- 如果相对URL以 / 开头(如 /images/logo.png),浏览器会把它直接替换到主机名后面的根路径,得到
https://www.example.com/images/logo.png。 - 如果以 ./ 或没有前缀开头(如 detail.html),浏览器会替换当前路径的最后一部分,得到
https://www.example.com/products/detail.html。 - 如果以 ../ 开头(如 ../css/style.css),就表示向上一级目录,浏览器会进行路径的回退和拼接。
这种设计的好处非常明显:可移植性和简洁性。当网站需要整体迁移到新域名或新目录时,使用相对URL的内部链接几乎无需修改。同时,在写代码时也省去了大量重复书写相同协议和主机名的麻烦,让HTML文件更干净。
浏览器在处理页面中的图片、链接、脚本的地址时,都在默默地执行这套基于“当前页面位置”的路径解析规则。它让网页内部的资源引用变得高效而易于维护,是Web架构中一个非常实用的设计。
1.1.5 从按下回车到浏览器开始处理服务器响应的这段时间里,具体发生了哪些关键步骤?
第一步,它得先理解你想干什么。 你输入 example.com 并回车。浏览器会想:“这是一个网址,还是想搜索这个词?” 它会根据规则(比如有没有点号、是否是一个有效的域名格式)来判断。通常,它会帮你补上缺的 http:// 或 https://,然后正式启动一次网页访问流程。
第二步,它翻看自己的“备忘录”。 在真正跑去网络之前,浏览器是个很“懒”的家伙,它会先到处查查有没有现成的。它先看本地缓存:这个网址的页面、图片等资源是不是不久前刚拿过,并且还没过期?如果是,可能直接就用了,连网络请求都省了。它还会看DNS缓存:example.com 对应的IP地址我还记得吗?如果都记不清了,它才不得不开始“外出办事”。
第三步,出门前的准备:找人问路和找对大门。 如果DNS缓存没有,它就要发起一次DNS查询,把域名翻译成IP地址。同时,它根据URL开头的 https,知道这是一次需要加密的对话,所以心里已经做好了要进行TLS安全握手的准备。它也开始准备和服务器建立TCP连接所需的“三次握手”流程。
第四步,正式派出“信使”(发送HTTP请求)。 当TCP连接(对于HTTPS,还包括TLS安全隧道)建立好后,浏览器就把早就准备好的那封“信”——也就是我们前面提到的HTTP请求报文——通过这个可靠的通道发送出去。这封信里写明了要哪个页面(路径)、客户端的偏好(请求头)等信息。
第五步,等待回音并拆阅。 请求发出后,浏览器就进入等待状态。当服务器的响应数据沿着网络传回来时,浏览器会先看到响应头。它迫不及待地检查第一行的状态码:如果是 200 OK,皆大欢喜;如果是 301 Moved Permanently,它就知道地址永久变了,要重定向;如果是 304 Not Modified,它会开心地从缓存里取出旧版本,省时省力。同时,它会看 Content-Type 这个重要的头,比如 text/html,这决定了它后续要启动HTML解析器来处理内容。
所以,在真正的网页内容(HTML)开始被解析之前,浏览器已经默默地完成了一次小型探险:理解意图、查找缓存、寻址问路、建立安全通道、发送请求、解读初步回信。这一整套前期工作,都是为了给后续的页面加载打下坚实的基础。每一层缓存检查都是为了速度,每一次握手都是为了可靠和安全。理解了这些,你就明白了网络性能优化和安全策略究竟是在哪个环节起作用。
1.1.6 如何观察浏览器解析和请求一个URL的过程?
最直接的办法是打开你常用浏览器的开发者工具(大多数浏览器按 F12 键就能打开)。然后,请你特别关注里面两个面板:
第一个是 “网络”(Network)面板。在你打开这个面板的状态下,清空列表(有个清除按钮),然后去地址栏输入一个网址并回车。这时,你会看到一个请求列表像瀑布一样流淌出来。列表里的第一行,通常就是你请求的那个主网页(比如 index.html)。
点击这一行,你会打开一个详情窗口。在这里,你能看到几乎所有我们之前讨论过的信息:
“标头”(Headers)标签页:这里完整展示了浏览器实际发出的请求URL、请求方法(GET/POST),以及下面所有的请求头信息。你可以一眼找到 Host、User-Agent、Cookie 这些我们提过的内容。往下翻,你还能看到服务器的响应头,比如状态码是不是 200,Content-Type 又是什么。
“预览”(Preview)或“响应”(Response)标签页:这能让你看到服务器返回的实际内容是什么,是HTML代码,还是一个JSON数据。
第二个值得一看的地方是开发者工具里的 “控制台”(Console)面板。你可以在里面输入一个简单的命令:document.location 然后回车。JavaScript会把这个当前页面的URL对象的所有组成部分(协议、主机、路径名、查询字符串等)清晰地打印出来。这是一种动态查看浏览器“眼”中当前页面完整URL结构的办法。
除了看浏览器的“内幕”,你还可以在操作系统的命令行里做一个小实验。打开“命令提示符”(Windows)或“终端”(Mac/Linux),输入 ping example.com(请换成一个真实的网站)。这个命令除了测试网络连通性,它第一行显示的内容,其实就是你的电脑在瞬间完成的 “DNS解析”结果——它已经把域名转换成了对应的IP地址。如果你想看更详细的DNS解析路径,可以试试 nslookup example.com 或 dig example.com 命令。
1.2.1 HTTP协议是什么?为什么说它是无状态的?
要理解HTTP,我们可以从它的名字开始:超文本传输协议(HyperText Transfer Protocol)。它的设计初衷很简单,就是为了在网络上请求和传输超文本文档(比如HTML)。你可以把它想象成一种约定好的“书信格式”,浏览器和服务器都按照这个格式写信、读信,这样才能互相理解。
那么,为什么说它是无状态的呢?这指的是协议本身不保留每一次请求之间的关联信息。服务器处理每个请求时,都像是第一次见到这个客户端一样,不会记得之前这个客户端做过什么。
这其实是一个设计上的权衡。早期的Web主要就是浏览静态文档,无状态的设计让服务器变得非常轻量,处理完一个请求就可以立刻释放资源,去服务下一个请求。这极大地提高了服务器的并发能力和可扩展性。试想,如果服务器要记住成千上万个用户之前看到哪一页,那得多复杂。
但这也带来了一个现实问题:我们很多应用是需要状态的,比如登录后的购物车。为了解决这个矛盾,人们发明了各种在无状态协议上构建状态的技术,比如Cookie和Session。Cookie相当于客户端带上的“通行证”,每次请求都出示一下,服务器看到通行证就知道你是谁了。所以,无状态是协议的底层特性,而上层应用可以通过额外手段来模拟状态。
简单来说,HTTP的无状态性不是缺陷,而是一个为了简单和高效做出的设计选择。这个选择推动了Web的早期快速发展,也催生了后来一系列有趣的技术。
1.2.2 HTTP请求方法中,GET和POST最主要的区别是什么?
GET和POST是HTTP里最常用的两个方法,它们最根本的区别在于语义,也就是它们所代表的“意图”不同。
GET的语义是“获取”资源。就像它的名字一样,GET是用来向服务器要东西的。因为目的是读取,所以GET请求通常不应该改变服务器上的数据。它发起的请求,所有参数都直接放在URL的查询字符串里(比如 ?id=123),因此是可见的,有长度限制,并且能被浏览器缓存、收藏。当你刷新页面或点击一个链接时,浏览器发起的通常就是GET请求。
比如,你打开我的文章,浏览器就会发送 GET 请求给服务器,服务器就会返回文章的所有文字及资源。
POST的语义是“提交”数据。它意味着客户端要向服务器发送一些数据,这些数据往往会改变服务器上的状态,比如发表一篇新文章、提交一个订单。POST请求的参数是放在请求的“身体”(Body)里发送的,对用户不可见,也没有长度限制,并且浏览器一般不会缓存POST请求的结果。这也是为什么你在网页上填完表单点击提交后,浏览器通常会问你是否要重新提交,因为它知道POST可能会改变数据。
比如,你在我的浪矢信箱里留言,点击“寄出信件”,浏览器就会执行一次 POST 请求,把你的留言文字放进了报文主体(body)里。然后拼接好 POST 请求头,通过 TCP 协议发送给服务器。
从安全角度来看,因为GET参数在URL里,所以它不适合传输敏感信息(如密码)。但更重要的是,由于GET的语义是读取,它被认为是“幂等”且“安全”的。幂等的意思是,多次执行相同的GET请求,效果应该和只执行一次一样,不会产生额外影响。安全则是指这个方法不应修改服务器数据。
而POST则既不幂等也不安全(在HTTP语义里)。提交一个订单多次,可能会创建多个订单,所以是不幂等的。因为会修改服务器的资源,所以是不安全的。
所以,选择GET还是POST,不是看数据大小,而是看你的意图是什么:是要获取数据,还是要修改数据?这个根本的语义区别,决定了它们在使用方式、缓存处理、浏览器行为上的所有不同。
1.2.3 HTTP 常见的状态码有哪些?
HTTP状态码是服务器在响应时,附在响应头里的一小段数字代码。它的作用就像我们平时对话里的简短回应:“好的”、“没找到”、“我错了”,让客户端第一时间知道这次请求的大致结果。
1xx(信息性状态码):表示请求已被接收,需要继续处理。比如100 Continue,客户端可以先发请求头,等服务器说“继续”再发请求体。平时在浏览器里不太常见。
2xx(成功):表示请求被成功处理。最常见的就是200 OK,一切顺利,响应体里就是你要的资源。
- 「
200 OK」是最常见的成功状态码,表示从客户端发来的请求在服务器被正常处理了。在响应报文内,随状态码一起返回的信息会因方法的不同而发生改变。比如,使用 GET 方法时,对应请求资源的实体会作为响应返回;而使用 HEAD 方法时,在响应中只返回头部,不会返回实体的主体部分。 - 「
204 No Content」也是常见的成功状态码,与 200 OK 基本相同,但在返回的响应报文中不含实体(enity)的主体(body)部分。 - 「
206 Partial Content」是应用于 HTTP 分块下载或断点续传,表示客户端进行了范围请求,响应报文中包含由 Content-Range 指定范围的实体内容。
3xx(重定向):表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 「
301 Moved Permanently」表示永久重定向,说明请求的资源已经不存在了,需改用新的URL再次访问。 - 「
302 Found」表示临时重定向,说明请求的资源还在,但暂时需要用另一个URL来访问。 - 「
304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
301 和 302 都会在响应头里使用字段 Location 指明后续要跳转的URL,浏览器会自动重定向新的 URL。
4xx(客户端错误):表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 「
400 Bad Request」表示客户端请求的报文有语法错误。浏览器会像 200 OK 那样对待该状态码。 - 「
403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。 - 「
404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx(服务器错误):表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 「
500 Internal Server Error」表示服务器端在执行请求时发生错误。 - 「
501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。 - 「
502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。 - 「
503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
理解状态码的关键,是把它看作服务器在完成请求处理后的一个“总结报告”。看到2xx,你就可以放心处理响应数据了;看到3xx,准备好跟随新的地址;看到4xx,你需要检查自己的请求是不是哪里写错了;看到5xx,那问题通常在服务器端,你可能需要等等再试。
1.2.4 HTTP的请求头和响应头是什么?
你可以把HTTP头(Header)想象成书信的信封和信纸上的附注。它们不是信件正文(请求体或响应体),而是关于这封信的各种元信息:谁寄的、什么时候寄的、用什么格式写的、应该怎么处理等等。
请求头是客户端(如浏览器)告诉服务器关于这次请求的附加信息;响应头是服务器告诉客户端关于这次响应的附加信息。它们都是以“键: 值”对的形式存在的。
我举几个最核心的例子:
在请求头里:
- Host:这是HTTP/1.1之后强制要求的一个头。因为一台服务器(同一个IP)可能托管了多个网站(比如 a.com 和 b.com),服务器必须靠这个头才知道你到底想访问哪个。它是实现“虚拟主机”的基础。
- User-Agent:告诉服务器客户端的身份(浏览器类型、版本、操作系统)。服务器有时会据此返回适配的页面(比如给手机和PC返回不同布局),但更常用于统计和分析。
- Accept 系列:这是“内容协商”的关键。Accept 告诉服务器“我偏好接收哪些媒体类型(如text/html)”,Accept-Encoding 说“我支持哪种压缩(如gzip)”,Accept-Language 说“我偏好哪种语言”。服务器会尽可能选择最合适的返回。
- Cookie:这是客户端存储的一小段文本,每次请求都会自动带上。它解决了HTTP无状态的问题,让服务器能识别用户会话。
在响应头里:
- Content-Type:这可能是最重要的响应头之一。它告诉客户端响应体的数据类型和字符编码,比如 text/html; charset=utf-8。浏览器就靠这个来决定是把内容当HTML渲染,还是当图片显示,或者当文件下载。
- Content-Length:指明响应体的字节大小,这样客户端就知道要接收多少数据。
- Set-Cookie:服务器通过这个头,要求客户端设置一个Cookie。下次请求时,客户端就会自动带上这个Cookie。
- Cache-Control:控制缓存的头,可以指定响应是否能被缓存、缓存多长时间(max-age)、是否必须向服务器验证等。它是现代Web缓存控制的核心。
理解这些头字段,其实就是理解HTTP通信的“潜规则”。它们不直接传递内容,但决定了内容如何被传递、处理和展示。
1.2.5 什么是HTTP缓存?它是怎么工作的?
想象一下,你每天都要看同一个新闻网站的头版。如果每次看,浏览器都要从遥远的服务器重新下载所有文字和图片,那会非常慢,也浪费网络流量。HTTP缓存就是为了解决这个问题:把一些不太会变的资源,在第一次获取后,存一份在本地,下次需要时直接使用。
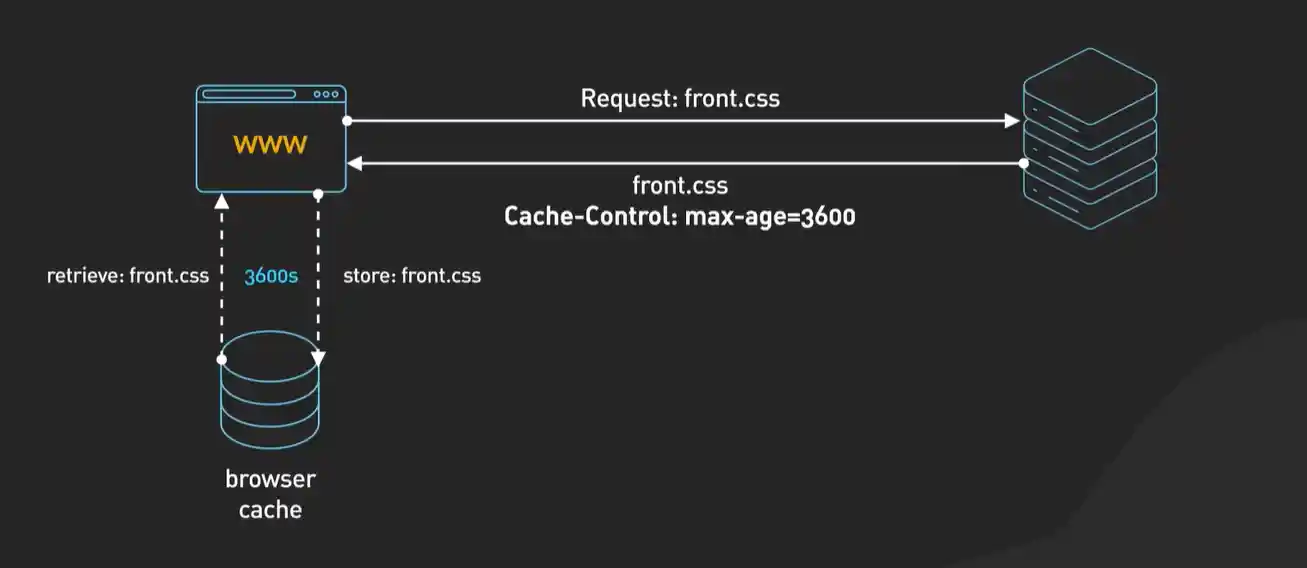
缓存工作的核心逻辑,可以用两个问题来概括:1. 这个资源能不能缓存? 2. 缓存过期了吗?
第一个问题,取决于服务器的“指示”。服务器在返回资源时,通过响应头(主要是 Cache-Control)告诉客户端这个资源能不能存、能存多久。比如 Cache-Control: max-age=3600 就意味着这个资源在本地可以缓存1小时(3600秒)。在这1小时内,浏览器再需要这个资源时,就会直接从本地缓存读取,根本不会发网络请求,速度最快。这叫做“强缓存”。
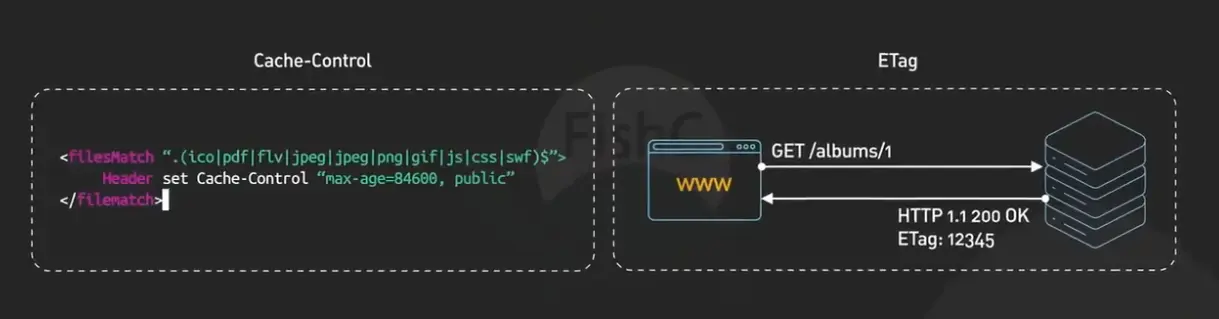
第二个问题,当缓存的时间(max-age)过了,资源“过期”了,浏览器不会直接扔掉它。而是会发起一个“条件请求”去问问服务器:“我本地有一份这个资源,是某年某月某日版本的(这个时间记录在 Last-Modified 头里),它还有效吗?” 这个请求会带上 If-Modified-Since 这样的头。服务器收到后,会对比一下这个时间,如果资源在这之后没改过,就返回一个极短的响应:304 Not Modified,并且不返回资源内容。浏览器一看304,就知道本地的缓存还能用,于是又从缓存里读取资源。这个过程叫“协商缓存”,它发起了请求,但节省了传输数据的带宽。

如果服务器资源已经变了,就会正常返回200和新的资源,浏览器更新本地缓存。
所以,一个设计良好的缓存策略(由服务器通过响应头控制),能极大地提升网站性能,减轻服务器压力。作为开发者,我们需要知道静态资源(如图片、CSS、JS)通常可以设置较长的缓存时间(比如一年),而动态页面(如HTML)则通常需要谨慎缓存或不缓存。
1.2.6 HTTP连接是如何被管理的?
要理解HTTP连接的管理,我们首先要回到一个基本现实:建立一次TCP连接(包括三次握手)是有成本的。如果每次发送一个HTTP请求都要经历一次完整的建立和断开过程,就像为了说一句话就专门打个电话,说完立刻挂断,这无疑是低效的。
因此,HTTP设计了一个叫做 “持久连接”(也叫HTTP Keep-Alive) 的机制。它的核心思想非常简单:在同一个TCP连接上,可以连续发送和接收多个HTTP请求和响应。这就像一次电话接通后,你可以和对方连续沟通好几件事,而不用反复重拨。
具体是怎么实现的呢?关键在于两个地方:
- 请求头中的 Connection:在HTTP/1.1中,默认就是持久连接。客户端发送请求时,通常会带有 Connection: keep-alive(尽管默认可省略),意思是“用完这次,先别挂”。服务器响应时也会表明同样的态度。
- 如何关闭:当任何一方决定结束这次“长谈”时,它会在自己发送的报文里加上 Connection: close,告诉对方:“这是本次连接上最后一个请求/响应了,处理完就挂断吧。”
那么,浏览器和服务器什么时候会决定“挂断”呢?这背后是一系列实用的考量:
- 超时机制:连接不可能无限期空闲。服务器通常会设置一个“空闲超时”时间(比如几秒到几分钟)。如果连接在这么长时间内没有任何新请求,服务器为了释放资源,就会主动关闭它。
- 请求数量限制:为了公平和防止单个连接占用资源太久,服务器或浏览器也可能规定“一个连接最多处理N个请求”,达到上限后就关闭并新建一个。
- 页面加载完毕:现代浏览器非常聪明。当一个网页的主HTML加载完毕后,它知道马上还要加载一堆CSS、JavaScript和图片。它会尽量复用现有的、健康的TCP连接来快速请求这些资源,而不是每个资源都重新握手。等整个页面加载得差不多了,这些连接在空闲一段时间后,才会被默默关闭。
所以,连接的管理本质上是在 “复用带来的效率提升” 和 “保持连接占用的资源成本” 之间寻找一个动态的平衡。理解这一点,你就明白了为什么查看开发者工具的“网络”面板时,你会发现有些资源的“连接ID”是相同的——它们正享受着持久连接带来的速度红利。
1.2.7 HTTPS到底“安全”在哪里?具体多做了哪几件关键的事?
我们可以把HTTP通信想象成寄明信片:内容谁都能看,路上还可能被调包。而HTTPS的目标,就是把这封“明信片”变成一封“防拆封的保密信件”。
它主要依靠两个核心技术来实现这个目标:加密和身份认证。
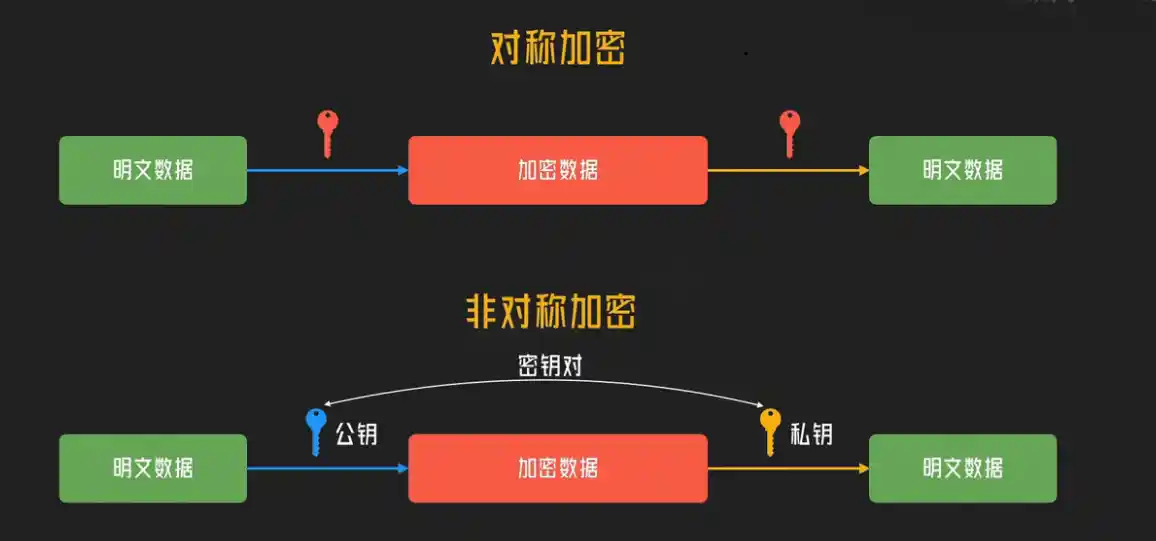
- 混合加密:保密性的核心
如果全程使用非对称加密(比如RSA),虽然安全,但计算太慢。如果全程使用对称加密(比如AES),速度快,但双方怎么安全地交换那个唯一的密钥呢?
HTTPS的智慧在于混合使用两者。它用非对称加密来安全地传递一个“会话密钥”(这个密钥本身是对称加密用的)。这个过程就像:我用你的公开的锁(公钥)把一个箱子的钥匙(会话密钥)锁起来寄给你,只有你有私钥能打开。钥匙安全送达后,我们后续大量的通信就用这把钥匙来加解密,效率就非常高了。
- 数字证书:身份认证的关键
加密解决了“别人听不到”的问题,但怎么解决“对方是不是骗子”的问题呢?这就是数字证书的功劳。
服务器在握手时,会出示它的“身份证”——由受信任的第三方机构(CA)颁发的数字证书。这个证书里包含了服务器的公钥、网站域名等信息,并且有CA的数字签名。你的浏览器里预存了各大CA的根证书(相当于公安局的印章备案)。浏览器会校验证书的签名是否真实、域名是否匹配、证书是否在有效期内。只有全部通过,它才相信:“嗯,对面确实是我想访问的那个网站,不是中间人伪装的。”
- 完整性保护:防篡改的保障
除了加密和认证,HTTPS还能确保数据在传输过程中没有被修改。它通过消息认证码(MAC) 等技术,为传输的数据打上一个“校验码”。接收方用协商好的密钥重新计算并比对,如果对不上,就说明数据在途中被篡改了,连接会被终止。
所以,HTTPS不是简单地给HTTP套个壳。它通过“混合加密”实现机密性,通过“数字证书”实现身份认证,再通过“完整性校验”防止数据被篡改。这三件事合在一起,才共同构建了一条从你的浏览器到目标服务器的、可信的、私密的通信隧道。你地址栏里的那个小锁图标,就是这条安全隧道建成的标志。
1.2.8 HTTPS是如何利用混合加密来保证通信安全的?
要理解HTTPS的加密设计,我们可以从一个现实问题开始:假设两个人需要在不安全的信道上秘密通信,他们面临两个选择——要么用同一把钥匙(对称加密),要么用两把不同的钥匙(非对称加密)。但无论选哪个,似乎都有麻烦。
对称加密的困境:如果双方用同一把钥匙加密和解密,效率很高。但问题来了:如何在不安全的信道上安全地把这把钥匙交给对方?如果直接发送钥匙,中途被截获,整个加密就毫无意义。这就好比你想用一把锁锁住送给朋友的箱子,但你必须先把钥匙寄给朋友——而寄钥匙的邮路同样不安全。
非对称加密的突破:于是人们发明了非对称加密。它有两把钥匙:一把公钥(可以公开给任何人),一把私钥(自己严格保密)。用公钥加密的内容,只有对应的私钥才能解密。这样,任何人想给你发秘密信息,都用你的公钥加密后发送,即使中途被截获,没有私钥也无法解密。这解决了密钥分发问题。但新的问题来了:非对称加密的计算非常复杂,速度比对称加密慢百倍甚至千倍。如果所有通信都用它,会慢得无法接受。
HTTPS的智慧:混合加密
HTTPS没有二选一,而是聪明地结合了两者,取长补短。整个流程分为两个阶段:
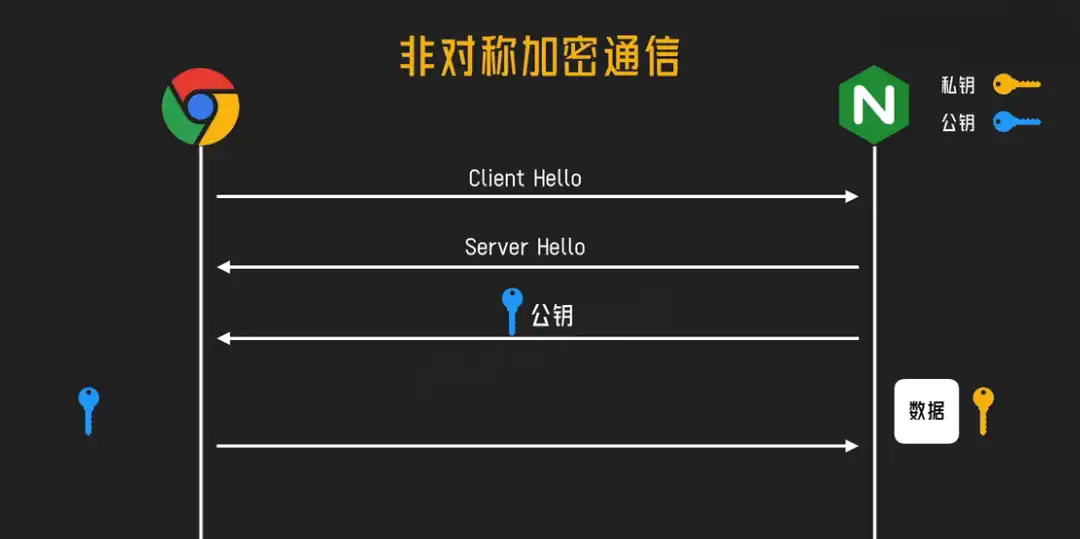
第一阶段:用非对称加密安全传递“会话密钥”
- 当你访问一个HTTPS网站时,服务器会先把它的公钥(包含在数字证书里)发给你。
- 你的浏览器会验证这个证书是否可信(确保公钥确实是目标网站的,而不是伪造的)。
- 验证通过后,浏览器生成一个随机的会话密钥(这是一把对称加密的钥匙)。
- 浏览器用服务器的公钥加密这把会话密钥,然后发送给服务器。
- 只有拥有对应私钥的服务器才能解密得到会话密钥。
这个过程完美解决了密钥分发问题:即使攻击者截获了加密的会话密钥,由于没有服务器的私钥,他无法解密。这就像你把一把真锁的钥匙放进一个特制的保险箱,只有收件人用只有他有的密码才能打开保险箱拿到钥匙。
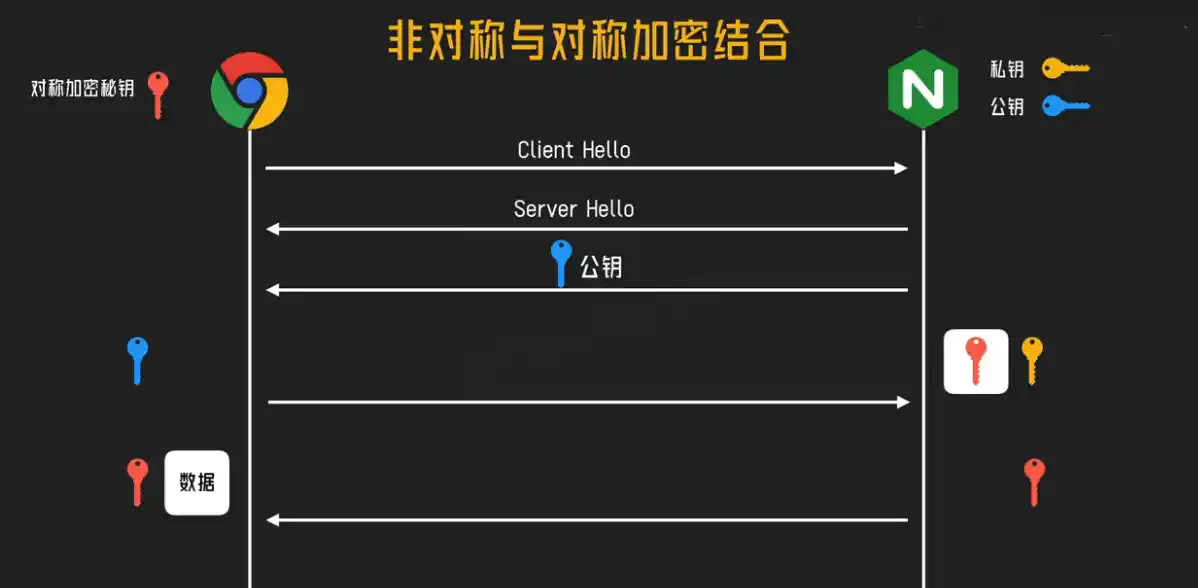
第二阶段:用对称加密高效通信
一旦双方都安全地拥有了同一把会话密钥,通信就切换到快速的对称加密模式:
- 浏览器用这把会话密钥加密请求数据,发送给服务器
- 服务器用同一把会话密钥解密后处理,再用它加密响应数据发回
- 整个过程高效快速,因为对称加密的计算开销很小
这个会话密钥是临时生成的,只在当前这次连接中有效。即使本次通信的加密被破解(概率极低),下次连接时又会生成全新的会话密钥,攻击者无法复用成果。
为什么这个设计如此精妙?
因为它严格遵循了“合适的工作交给合适的工具”这一工程原则:
- 非对称加密负责最初的关键任务:安全地传递一个很小的秘密(会话密钥)。虽然它慢,但只用在握手阶段,完全可接受。
- 对称加密负责重头戏:加密实际的海量通信数据。它速度快,确保了日常浏览的流畅体验。
这就像两国元首要进行秘密会谈:
- 首先派特使用防弹装甲车(非对称加密)运送一本绝密的密码本(会话密钥)到对方手中。
- 之后的所有日常通信,双方就用这个密码本(对称加密)来加密电报,既安全又高效。
1.2.9 如果有一个假基站作为中间人转发所有流量,HTTPS还能保证我的通信安全吗?
这是一个非常实际的场景。假基站(比如一个恶意的蜂窝基站或Wi-Fi接入点)确实可以迫使你的设备连接到它,然后由它来转发你与真实互联网之间的所有数据。在这种情况下,HTTPS的安全性面临一次真正的考验,但结果未必如攻击者所愿——HTTPS的设计恰恰是为了应对这种威胁。
我们可以分两种情况来看:
情况一:假基站只做“透明转发”
如果假基站只是像一根网线或者一个简单的路由器那样,原封不动地转发加密的数据包,那么它什么也得不到。因为HTTPS的通信从第一个关键握手包开始就是加密的(TLS 1.3下更彻底),假基站看到的只是一堆毫无意义的乱码。它不知道你们协商的密钥,无法解密任何内容。这就像邮差可以转交一个上了锁的保险箱,但他没有钥匙,根本不知道里面装了啥。
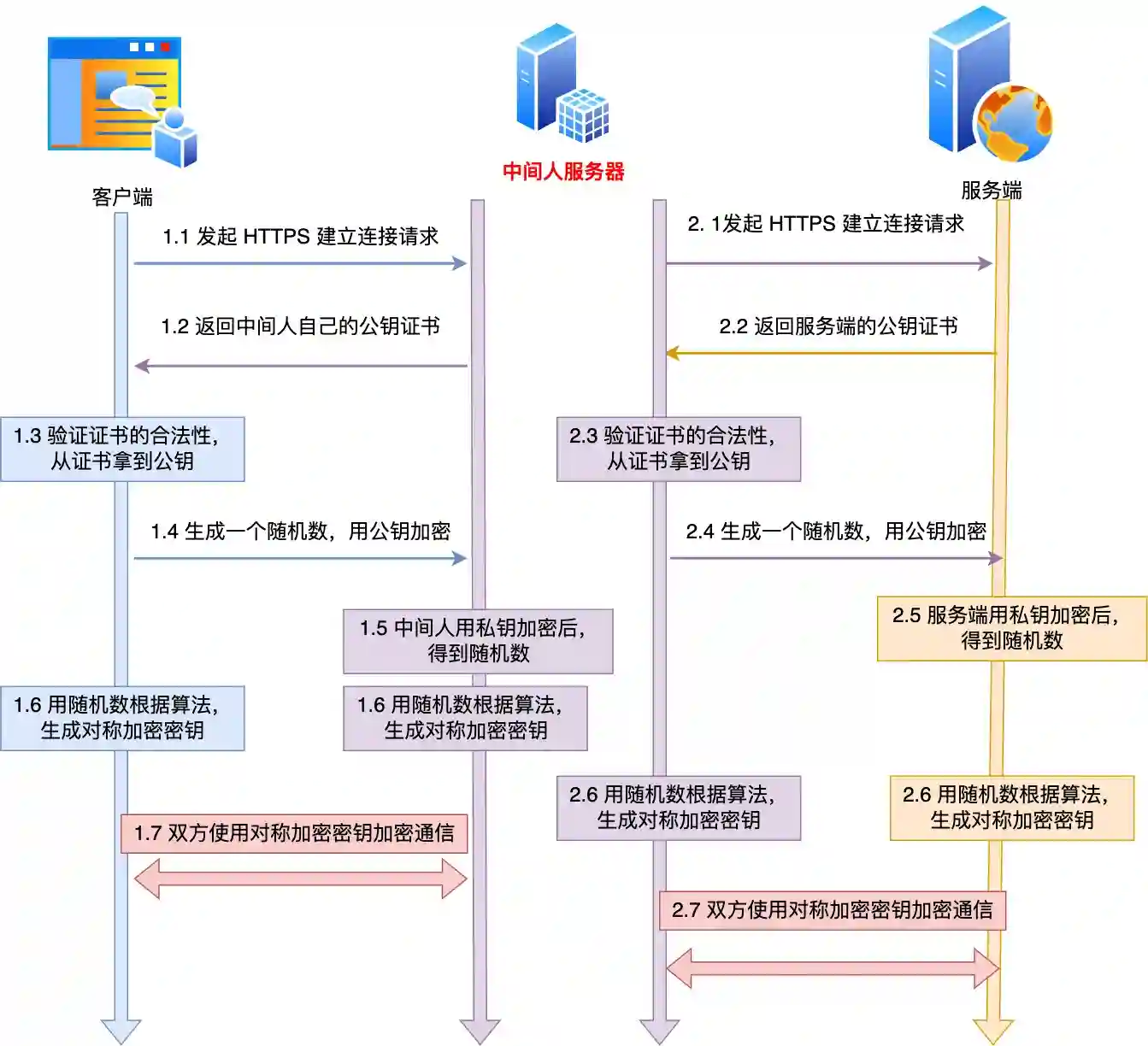
情况二:假基站进行“主动劫持”(这才是真正的威胁)
聪明的攻击者不会满足于只当“邮差”,他会试图扮演“假银行”和“假客户”的双重角色。具体步骤是:
- 对你冒充银行:当你的浏览器尝试连接
https://yourbank.com时,假基站会截获这个请求,并立刻伪装成银行服务器,向你发送一个伪造的数字证书。 - 对银行冒充你:同时,假基站自己与真正的银行建立另一个HTTPS连接。
如果这个骗术成功,假基站就能坐在你和银行之间:它用你的密钥解密你发来的数据,看完、记下甚至改掉,再用银行的密钥加密后发给银行;反过来也一样。这样,它就成了一个全知全能的中间人。
HTTPS如何破这个局?关键在于“证书验证”
当你(浏览器)收到假基站发来的伪造证书时,并不会轻易相信。它会启动一套严格的验证程序:
- 检查签发者:这个证书是谁发的?如果是一个你自己从未安装过的、不被操作系统信任的机构(比如“假基站自制CA”),浏览器会立刻弹出红色警告,明确阻止你继续访问。
- 检查域名:即使证书来自某个受信任的机构,浏览器也会检查证书上写的域名是否与你正在访问的 yourbank.com 完全一致。如果不一致,同样会警告。
- 检查吊销状态:浏览器还会在线查询该证书是否已被原主人作废。
对于主流网站,攻击者几乎不可能获得一张由正规受信机构签发、且域名匹配的有效证书。因此,在假基站场景下,你大概率会看到浏览器的全屏安全警告。
那么,假基站攻击在什么情况下会成功?
成功需要同时满足两个苛刻条件:
- 技术上:攻击者能提供一张受你设备信任的、目标域名的有效证书。
- 人为上:你选择忽略浏览器的强烈警告,执意继续访问。
第一个条件极难实现,除非发生了国家级别的攻击(控制了正规CA)或你的设备被预先植入了恶意根证书(比如一些企业监控电脑或恶意软件所为)。而第二个条件,则完全取决于你的安全意识。
给普通用户的建议
- 绝对不要忽略浏览器的证书警告。当看到“您的连接不是私密连接”、“此网站的安全证书存在问题”等警告时,立即停止访问,尤其涉及银行、支付等敏感操作时。
- 在公共场所连接Wi-Fi时,留意网络名称。假基站常伪装成“Starbucks FREE”、“Airport WiFi”等常见名称诱导连接。
- 观察网址栏。确认访问的是 https:// 开头,并且带有一个锁形图标。点击锁图标可以查看证书详情,确认颁发给(Issued to)的域名是否正确。
1.2.10 简单描述一下HTTPS握手的具体步骤
我们把HTTPS握手想象成两个陌生人在一个嘈杂的广场上,想要建立一个只有他俩能懂的秘密通信方式,并且还要确认对方的身份。这个过程确实需要几个来回,每一步都有明确的目的。
一个典型的TLS 1.2握手大致是这样的:

第一步,客户端打招呼(Client Hello)。客户端(比如你的浏览器)会向服务器发送一条消息,里面包含:我支持的最高TLS版本号、一个客户端生成的随机数、以及一份我支持的密码套件列表(比如“RSA加密,AES对称加密,SHA256校验”)。这相当于说:“嗨,我想用加密方式聊天,这是我的能力和一个随机数A。”
第二步,服务器回应并出示证书(Server Hello, Certificate, Server Hello Done)。服务器收到后,会从客户端的列表里选出一个双方都支持的、最安全的密码套件,也生成一个服务器随机数,连同自己的数字证书一起发给客户端。证书里就包含了服务器的公钥。这相当于服务器回答:“好的,我们就用AES-256这套密码吧,这是我的随机数B,还有我的‘身份证’(证书),请你查验。”
第三步,客户端验证证书并生成密码(Certificate Verify, Client Key Exchange)。这是关键一步。客户端(浏览器)会动用自己内置的CA根证书,去验证服务器的证书是否真实有效、是否过期、域名是否匹配。只有验证通过,它才信任对方。然后,客户端会生成一个“预主密钥”,并用刚才从证书里拿到的服务器公钥加密它,发送给服务器。同时,客户端结合之前的随机数A、B和这个预主密钥,已经可以计算出后续通信用的“会话密钥”了。
第四步,服务器解密获得密码(Server Finish)。服务器用自己的私钥解密得到预主密钥,现在它也有了随机数A、B和预主密钥,因此也能计算出同样的“会话密钥”。
第五步,双方安全通信开始。从此刻起,双方就用这个只有他们俩知道的“会话密钥”进行快速的对称加密通信了。
你看,这个过程之所以不能更简单,是因为它要安全地完成三件大事:协商密码(交换随机数)、验证身份(检查证书)、安全传递密钥(用公钥加密预主密钥)。任何试图跳过步骤的简化,都可能牺牲安全性。比如,如果不验证证书,就可能遭遇“中间人攻击”;如果不交换随机数,每次生成的密钥就可能不够随机;如果不用非对称加密传递密钥,密钥本身在传输中就可能被窃听。
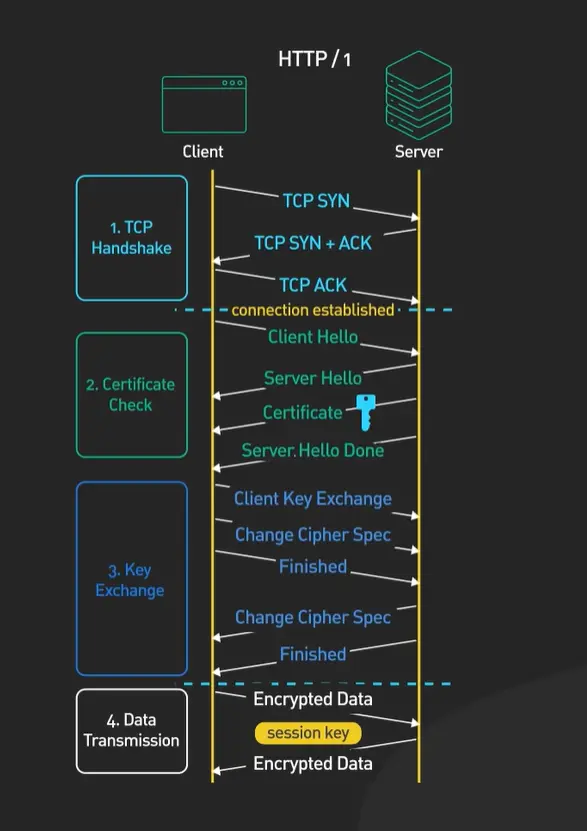
所以,HTTPS握手的“复杂”是一种必要的复杂,是用几次往返的时间成本,换来了整个通信过程的机密性、完整性和身份认证。后续的HTTP/3(QUIC)通过将TLS 1.3深度集成到协议中,已经将这个握手过程优化到了极致(通常只需1次往返),但这套安全逻辑的核心依然被保留了下来。安全与效率的权衡,始终是网络协议设计中最迷人的课题之一。
1.2.11 Cookie是做什么用的?
HTTP协议本身是“健忘”的(无状态),它不记得你上一次来过。但很多服务需要“记住”用户,比如保持登录状态、记录购物车里的商品。Cookie就是为解决这个问题而生的“小纸条”机制。
你可以把Cookie想象成服务器发给浏览器的一张会员卡。服务器在第一次接待你(比如你登录成功)时,会在HTTP响应头里加上一行:Set-Cookie: session_id=abc123; Path=/。这相当于说:“这是你的会员卡号,下次来记得带上。”
浏览器收到这张“卡”后,会非常负责地把它存起来,并且关联到发卡的域名。从此以后,每当浏览器再向同一个域名发送请求时,它都会自动在请求头里附上这张“卡”:Cookie: session_id=abc123。这就好比你去一家店,每次进门都自动出示会员卡,店员(服务器)看到卡号,就能从自己的数据库里调出你的档案(会话信息),知道你是已经登录的VIP用户了。
这里有几个关键的细节设计:
- 作用域控制:Set-Cookie 时可以指定 Domain 和 Path。比如 Path=/shop,意味着只有访问该网站 /shop 目录下的页面时,浏览器才会带上这个Cookie。这就像会员卡注明“仅限本店二楼使用”。
- 有效期:可以设置为会话级(浏览器关闭就失效),也可以设置一个具体的过期时间(Expires 或 Max-Age)。
- 安全标记:HttpOnly 标记让JavaScript无法读取这个Cookie,主要用于防止跨站脚本攻击(XSS)窃取会话信息。Secure 标记要求只有在HTTPS连接时才会发送Cookie。
- 大小限制:每个Cookie通常不超过4KB,一个域名下的Cookie数量和总大小也有限制。
所以,Cookie本质是服务器委托浏览器在本地帮忙存储一点关键识别信息,并由浏览器在后续访问中自动回传的协作机制。它完美地弥补了HTTP无状态的不足,是Web会话管理的基石。你之所以能在关上浏览器再打开后,依然保持某些网站的登录状态,通常就是因为那个Cookie的有效期还没到。
1.2.12 从HTTP/1.0到HTTP/1.1,发生了哪些关键变化?
如果我们把HTTP/1.0看作是网络通信的“早期实验版本”,那么HTTP/1.1就是一次重要的“定型量产”。它的改进不是为了炫技,而是为了解决早期版本在实际大规模使用时暴露出的种种不便。
最核心的一个变化,就是我们之前提过的持久连接(默认开启Keep-Alive)。在HTTP/1.0里,每个请求-响应都会新建和断开一个TCP连接,这就像为每件小快递都单独派一辆车,派完就销毁,极其浪费。HTTP/1.1默认让这个连接保持一段时间,以便运输更多的“包裹”,这极大地减少了网络延迟和系统开销。这个决定直接源于一个基本事实:建立一个可靠连接的成本,远高于在现有连接上多传输一点数据。
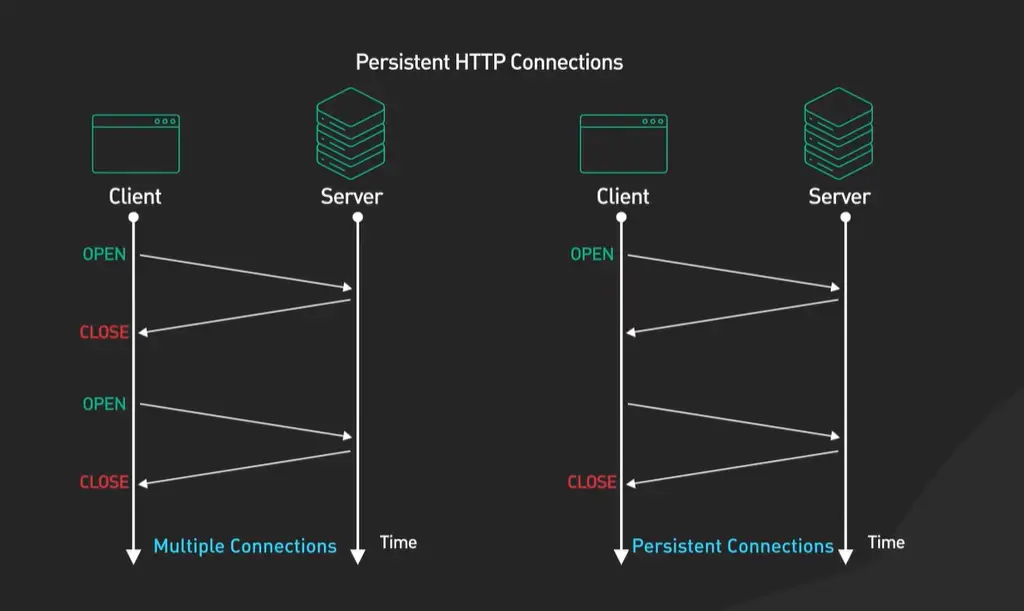
另一个看似微小但影响深远的变化是引入了Host请求头。在HTTP/1.0时代,一台服务器(一个IP地址)通常只服务一个网站。但随着网络发展,人们希望在一台物理服务器上托管多个网站(虚拟主机)。如果没有Host头,服务器收到请求时,根本不知道客户端想访问的是它身上托管的哪个网站。Host: www.site-a.com 这个头的加入,完美地解决了这个问题,它让Web托管成本得以大幅降低,是支撑现代互联网网站海量增长的一个小基石。
此外,HTTP/1.1还增加了很多增强功能的头字段,比如为了支持断点续传的Range头,为了更精细控制缓存行为的Cache-Control头(比HTTP/1.0简单的Expires更强大)。它还正式明确了管道化的支持(尽管在实践中用得不多),允许客户端在未收到响应时就发送下一个请求,试图进一步提升效率。
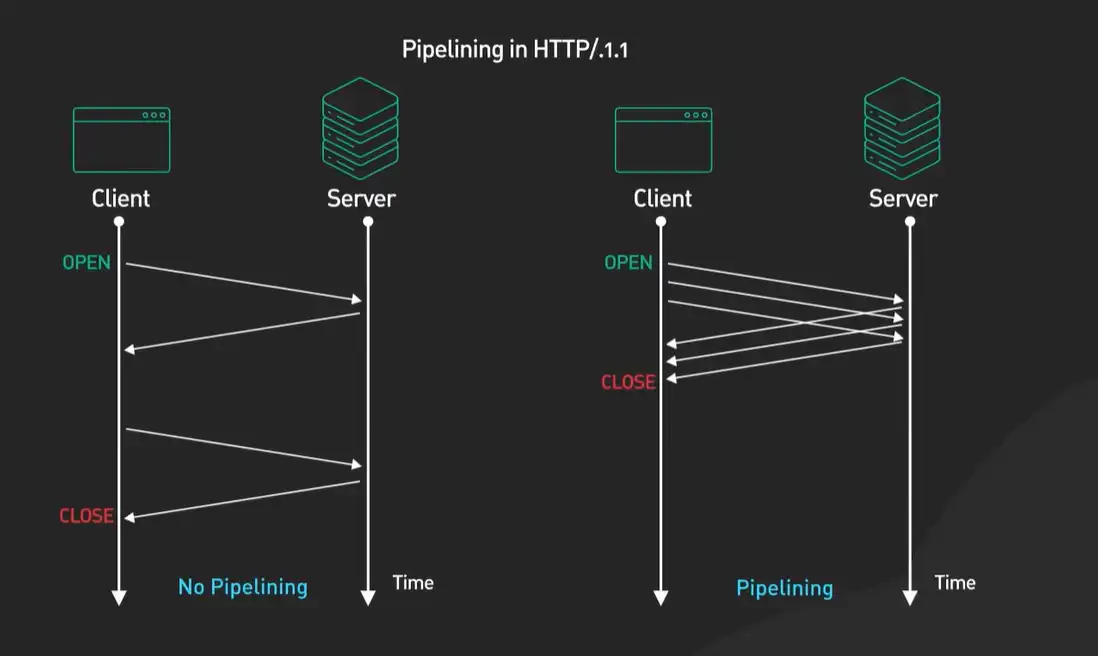
所以,从HTTP/1.0到1.1的演进,是一部典型的“从理想模型走向复杂现实”的工程史。它没有改变HTTP的根本设计,而是通过打上一系列务实的“补丁”,来应对真实世界对性能、成本和灵活性的苛刻要求。这些补丁打下了坚实的基础,也最终暴露了其设计的极限,从而催生了HTTP/2的革命。
1.2.13 在HTTP/1.1中,什么是“队头阻塞”?浏览器通常用什么办法来缓解它?
“队头阻塞”这个听起来有点专业的名词,描述的问题其实很直观。在HTTP/1.1的持久连接上,虽然可以发送多个请求,但这些请求必须是“一个接一个”串行发送的。
想象一下,你在一个只有一个收银台的超市排队。你买了很多东西,但前面有一个人买了一件需要经理来授权的特殊商品,卡住了。那么就算你只买一罐可乐,也只能干等着。在网络中,如果第一个请求需要很长时间(比如等待一个大的数据库查询),后续已经准备好的请求也得在“队头”后面苦苦等待,无法被发送出去。这就是“队头阻塞”。
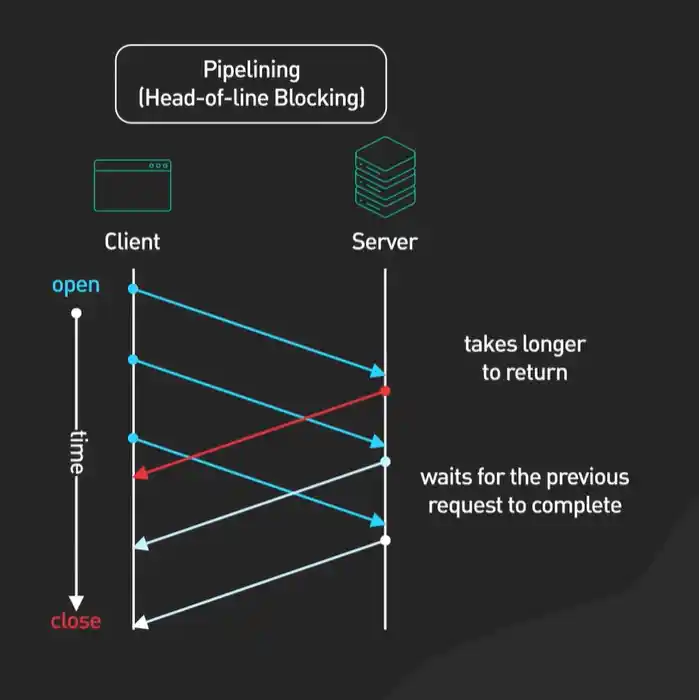
为了缓解这个严重影响页面加载速度的问题,聪明的浏览器工程师们想出了两个主要的“土办法”:
- 多开几个“收银台”(建立多个TCP连接):这是早期浏览器最直接的策略。老的标准通常允许对同一个域名同时打开6个左右的TCP连接。这样,浏览器可以把多个资源(如图片、CSS)分别放到不同的连接通道上去请求,绕开了单个连接上的队头阻塞。你在开发者工具里看到很多资源并行下载,就是这么来的。
- “点餐”和“取餐”分开(域名分片):既然一个域名最多开6个连接,那我把资源分散到多个不同的子域名下不就行了?比如把图片放到 img1.example.com、img2.example.com。这样,浏览器就能为每个子域名再打开最多6个连接,极大地增加了并行度。这本质上是对浏览器规则的一种“钻空子”式的优化。

但是,请务必注意,这两种方法都只是缓解,而不是解决。它们增加了建立和管理连接的成本(更多的TCP握手和TLS握手),也增加了服务器的负担。队头阻塞的根本症结——HTTP层请求/响应的严格串行——在HTTP/1.1的框架内是无解的。
正因为这些“土办法”既复杂又不够完美,才催生了新一代的协议HTTP/2,它从底层改变了游戏规则,我们会在后面的问题中谈到。理解“队头阻塞”和这些缓解措施,能让我们真正体会到HTTP/2所做的改进是多么的迫切和重要。
1.2.14 HTTP/2相比HTTP/1.1,最革命性的改进是什么?
如果说HTTP/1.1的优化像是在狭窄的乡间小道上努力增加车道,那么HTTP/2就像是直接修建了一条现代化的高速公路。它最革命性的改进,是引入了一个全新的概念:二进制分帧层。
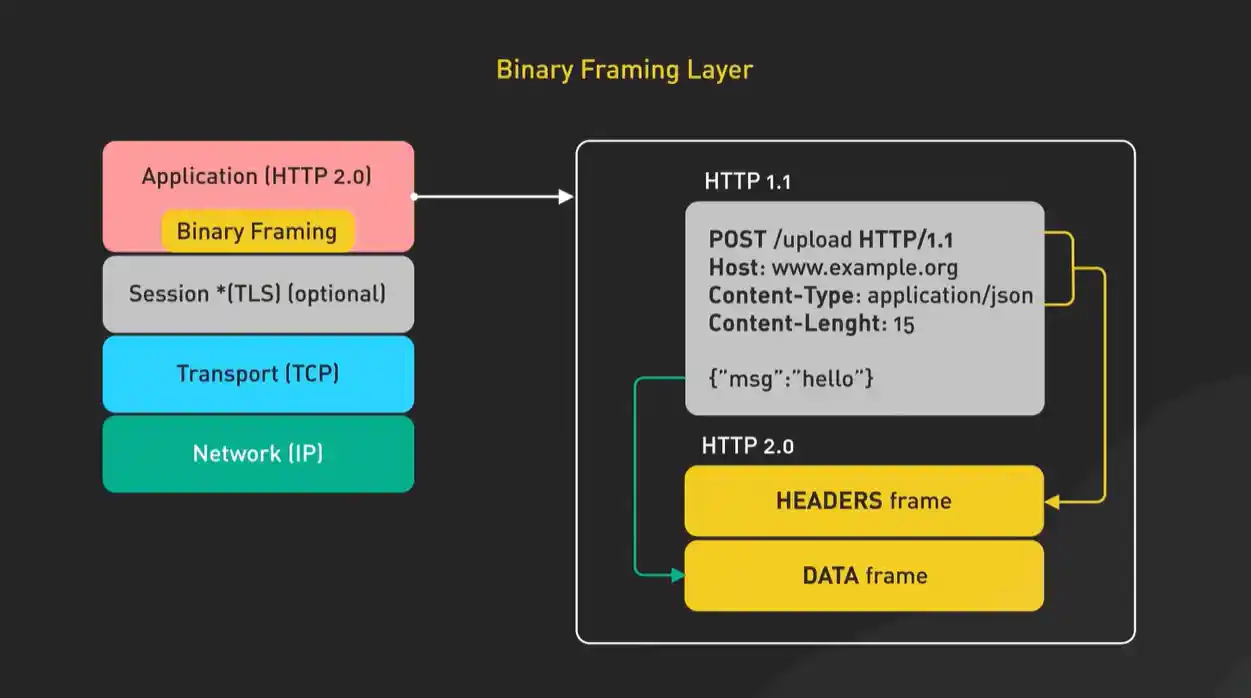
在HTTP/1.1中,报文是纯文本格式的(我们前面看到的那些头信息),这虽然对人类友好,但对机器处理来说效率不高,且必须按顺序解析。HTTP/2把请求和响应都拆解成了更小的、带有ID编号的二进制帧。这些帧可以乱序发送,然后在接收端根据ID重新组装。
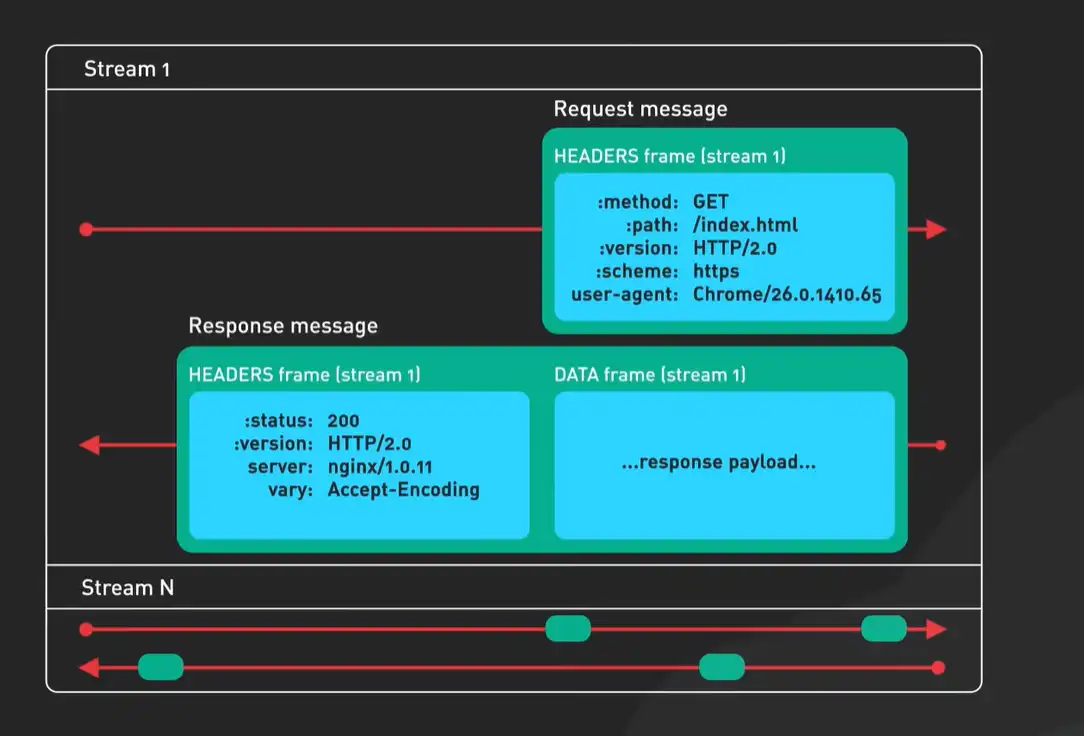
基于这个强大的二进制分帧层,HTTP/2实现了几个“魔法般”的特性:
- 多路复用:真正的并行
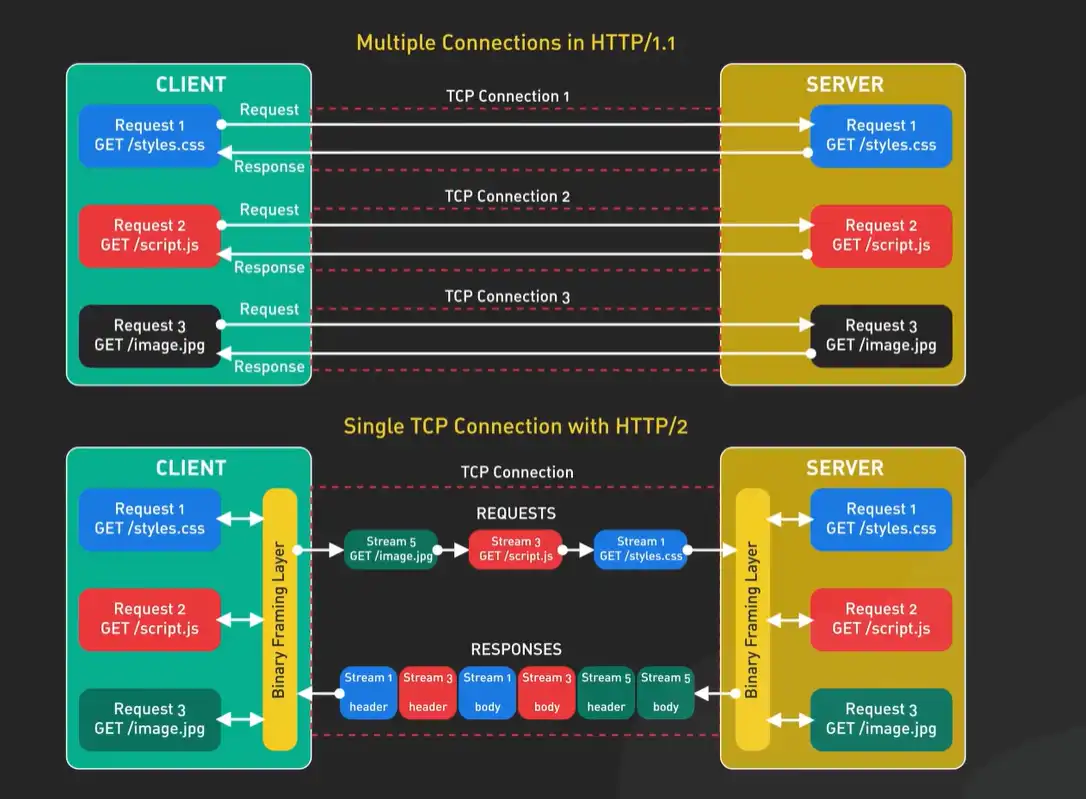
这是解决队头阻塞的终极方案。在同一个TCP连接里,现在可以同时交错发送多个请求和响应的帧。比如,请求A发了一部分帧,请求B的帧可以立刻插队发送,不用等A的响应全部回来。这就像在一条高速公路上,不同车辆(请求)的零部件(帧)可以并行运输,到达终点后再组装成完整的车。从此,浏览器不再需要为单个域名建立多个连接,一个连接就能搞定所有。
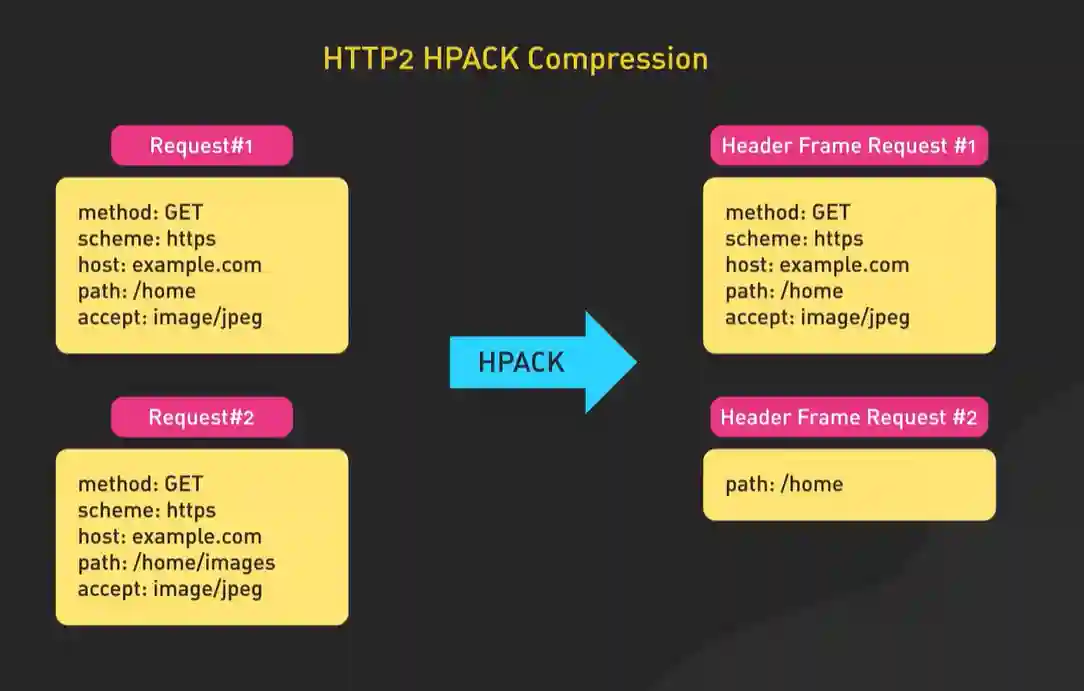
- 头部压缩:减负利器
HTTP的头部(特别是Cookie)经常重复且臃肿。HTTP/2使用专门的HPACK算法对其进行压缩。通信双方维护一份相同的“静态表”(包含常见头部字段)和“动态表”(记录本次连接出现过的头部)。后续传输只需要发送字段的索引号,极大地减少了冗余数据。
- 服务器推送:未问先答
这是一个非常主动的优化。服务器可以“猜测”客户端在请求一个HTML页面后,很可能还需要相关的CSS和JavaScript文件。于是,它可以在返回HTML响应的同时,主动把这些关联资源“推送”给浏览器,而不必等浏览器解析HTML后再一个个发起请求。这相当于服务员在你刚点完主菜时,就根据经验把你可能需要的餐具和配菜一并送了上来。
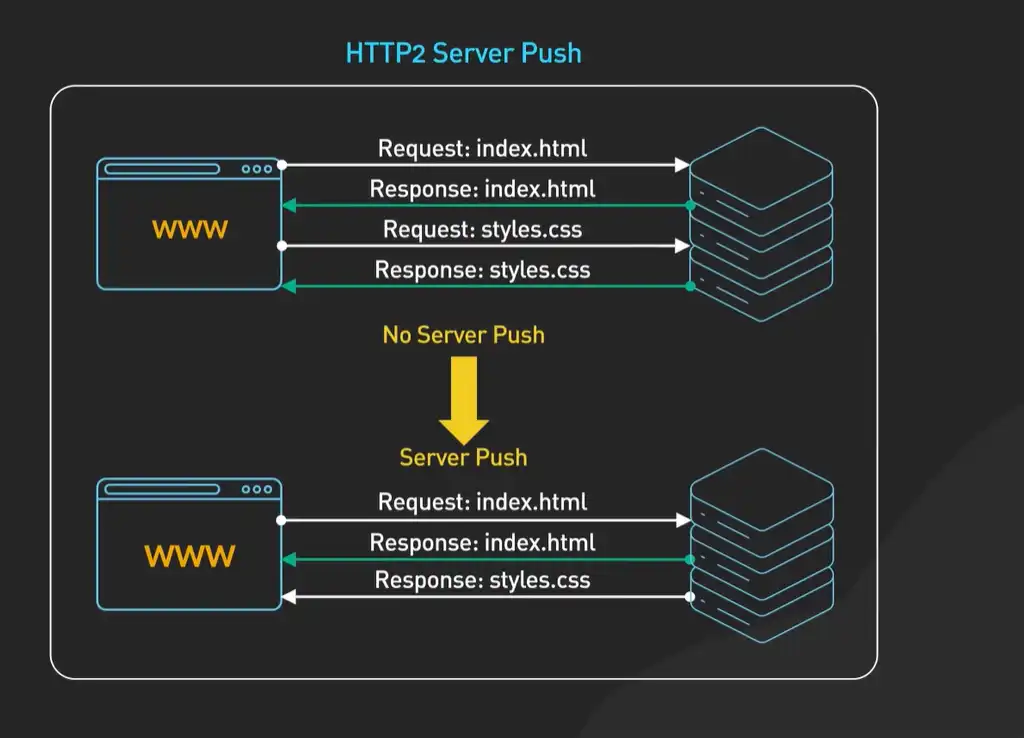
所以,HTTP/2的革命性在于,它不再是在应用层(文本命令)上修修补补,而是在传输层之上重新定义了一套更高效的通信语言(二进制帧)。多路复用彻底解决了队头阻塞,头部压缩大幅提升了效率,服务器推送则开启了新的优化维度。所有这些特性,都依赖于那层看不见的、高效的二进制分帧层,它才是HTTP/2高速公路的基石。
1.2.15 HTTP/2为什么一定要转向二进制协议?
我们都会觉得文本协议很友好,用GET /index.html HTTP/1.1这样一句话就能指挥计算机,多直观啊。但计算机网络的本质是机器与机器对话,而不是让人去阅读。当性能要求达到极致时,文本协议这种“对人类友好”的特性,反而成了“对机器不友好”的负担。
文本协议的第一个问题是解析效率低。计算机处理文本需要逐个字符地读取、判断边界(比如哪里是行尾、哪里是头结束),这涉及到大量的状态检查和字符比较,很容易出错且速度慢。而二进制协议,数据以严格的、预定好的格式和长度排列,计算机几乎可以直接按位置“抓取”需要的信息,解析起来又快又准。
第二个更关键的问题是文本协议的灵活性陷阱。文本协议为了可读性,允许很多“便捷”的写法,比如行尾可以用\r\n也可以用\n,头部名称大小写不敏感,空白字符的处理方式多样等等。这种宽松性导致不同的实现(不同的浏览器、服务器、中间代理)可能在解析时产生微妙的差异,甚至引发安全漏洞。二进制协议从设计上就杜绝了这种歧义,格式非常严格,实现起来更一致、更安全。
HTTP/2转向二进制的根本动力,其实是为了给它那些革命性的新功能铺平道路。比如多路复用,它需要在同一个连接里交错传输多个请求和响应的碎片。如果用文本格式,你很难清晰、无歧义地标出“这一块数据是属于哪个请求的”。而二进制帧就像乐高积木,每个帧都明确带有流ID、类型、长度等“标签”,机器可以毫无困难地识别、排序和组装。再比如头部压缩,对文本进行高效压缩本就比二进制复杂,HTTP/2的HPACK算法正是建立在二进制帧的稳定结构之上。
所以,这不是一个“行不行”的问题,而是一个“要不要追求极致”的选择。HTTP/1.1的文本协议就像用自然语言写复杂的法律条文,虽然能看懂,但冗长且易产生歧义。HTTP/2的二进制协议则像用严谨的数学符号和格式合同来书写,对机器极度友好,为实现更复杂、更高效的通信提供了可能。它牺牲了一点人类的直接可读性,换来了整个网络性能和安全性的巨大提升。
1.2.16 HTTP/2的多路复用具体是怎么工作的?为什么它能把一个TCP连接用得这么“满”?
你可以把一个HTTP/2的连接想象成一条宽阔的高速公路,而HTTP/1.1的连接就像一条狭窄的单车道。多路复用的魔法在于,它把这条高速公路划分成了多条逻辑上的“虚拟车道”,并且给每辆“车”(即每个请求)都分配了一条专属车道。
技术上,这是通过流的概念实现的。每个HTTP请求/响应交互都被分配一个唯一的流ID。当浏览器要发起多个请求时,它不再排队,而是把这些请求分别切成更小的帧(比如HEADERS帧承载头信息,DATA帧承载主体数据),然后把这些来自不同流的帧混合在一起,通过同一个TCP连接发送出去。
关键在于,这些帧的传输是乱序的。来自流1的DATA帧可能才发了一半,来自流10的HEADERS帧就可以插进来发送。接收端(服务器或浏览器)的工作就是根据每个帧头部的流ID,像拼图一样,把所有属于同一个流的帧收集起来,重新组装成完整的请求或响应。
这个过程彻底解决了HTTP层的队头阻塞。在HTTP/1.1中,一个缓慢的请求会堵住后面所有请求的发送通道。而在HTTP/2中,即使流1的响应因为服务器处理慢还没回来,流2、流3的请求帧和响应帧依然可以在连接中自由穿梭,互不影响。这极大地提升了连接的利用效率,这也是为什么HTTP/2通常只需要一个TCP连接就能处理整个页面的所有请求。
不过,这里有一个重要的细微之处需要理解:HTTP/2解决了HTTP层的队头阻塞,但TCP层的队头阻塞依然存在。因为TCP协议本身要保证数据按顺序交付。如果流1的一个帧在传输中丢失了,TCP为了重传这个丢失的帧,会导致后续所有流的帧(即使它们已经正确到达接收端的TCP缓冲区)都被阻塞,无法被HTTP/2层读取。这就好比高速公路的一段路基塌了,虽然其他车道是好的,但整个方向的车流都得停下等待修复。这个TCP层的固有限制,正是催生HTTP/3的深层原因之一。
1.2.17 为什么我们还需要HTTP/3?
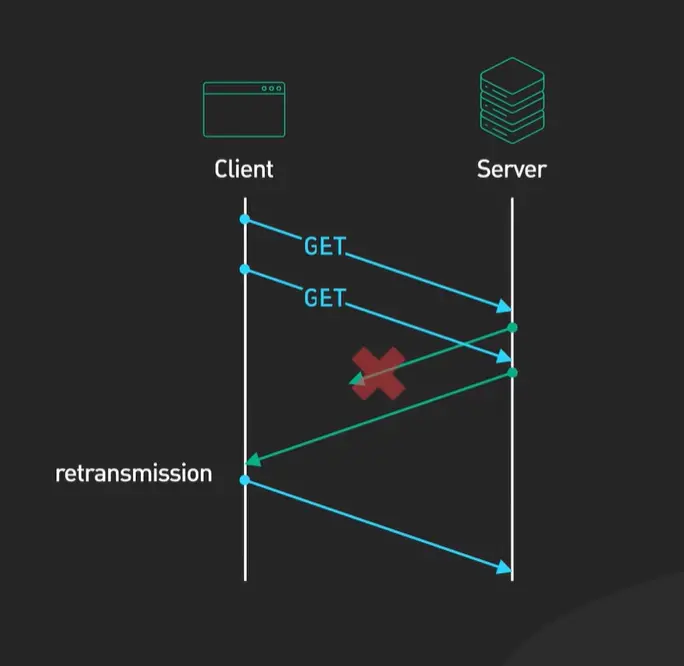
这是一个触及网络协议演进根源的问题。HTTP/2的诞生,是为了解决HTTP/1.1在应用层设计的低效。但它依然运行在TCP协议之上,这就把它和TCP协议几十年来的一个老问题捆绑在了一起:TCP的队头阻塞和握手延迟。
我们刚才提到,即使HTTP/2实现了完美的多路复用,一旦有一个TCP包在传输中丢失,整个TCP连接就必须停下来等待这个包重传成功。在这段等待期里,所有HTTP流都会被卡住。在网络条件差(比如高丢包率的移动网络)的情况下,这个问题会非常明显,HTTP/2的性能优势甚至可能被抵消。
另一个问题是TCP的握手。建立一个新的TCP连接需要三次握手,建立TLS安全连接还需要额外数次往返。即使有连接复用,但在移动设备切换网络、或连接超时断开后,重建连接的成本依然很高。
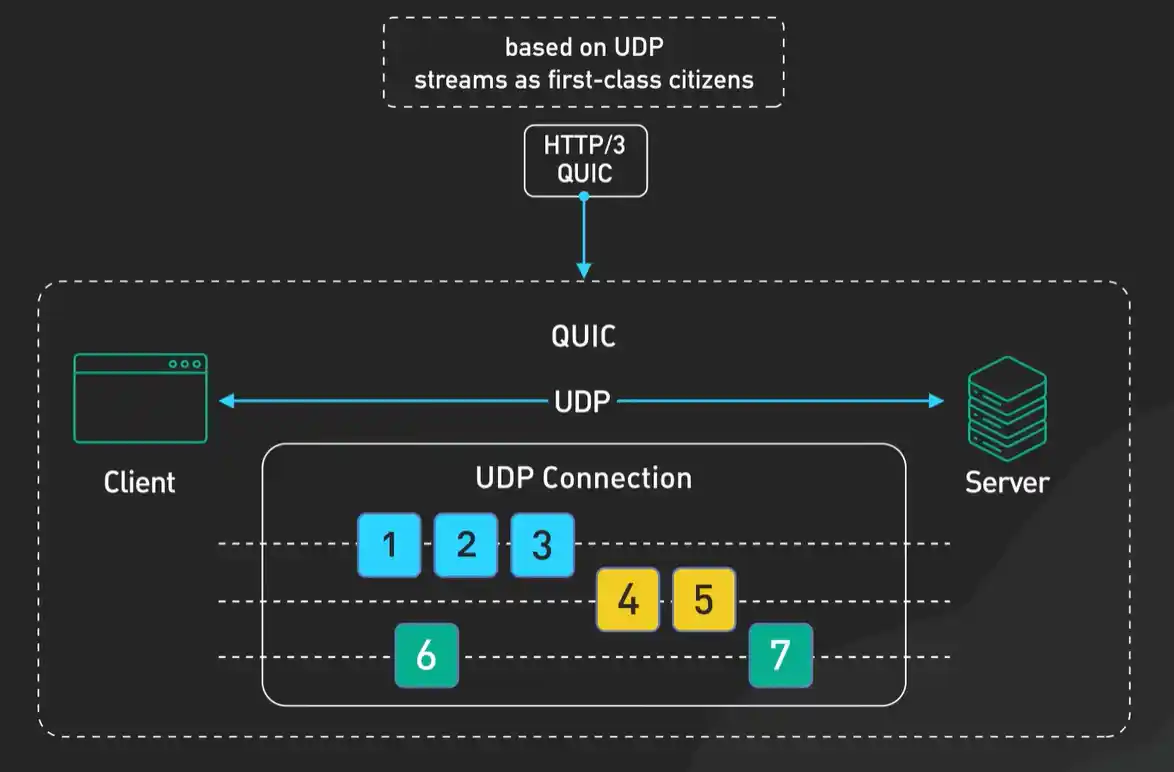
于是,HTTP/3做了一个大胆的决定:彻底抛弃TCP,转而基于UDP协议,并在其上实现了全新的QUIC协议。这听起来有点不可思议,UDP不是不可靠的吗?没错,但QUIC(发音:quake)协议在UDP的基础上,重新实现了一套包含了可靠传输、拥塞控制、安全加密的完整机制。你可以把QUIC理解为“在用户空间实现了TCP+TLS的精华,并加以改进的新传输协议”。
这样做带来了几个关键好处:
- 真正消除了队头阻塞:QUIC在单个“连接”内部也为每个流提供了独立的包序列和丢失恢复机制。一个流的包丢了,只会重传那个流的包,其他流的传输完全不受影响。
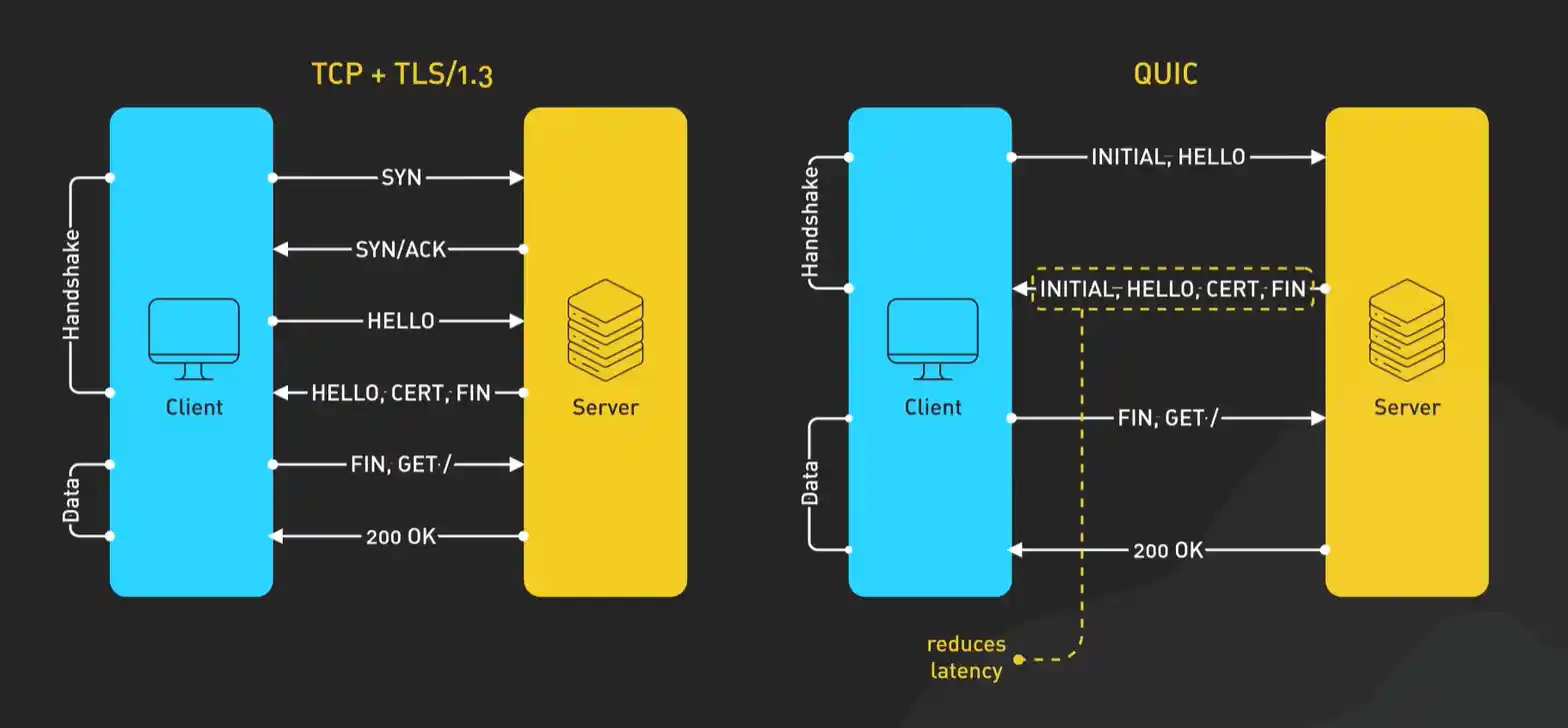
- 大幅减少连接建立时间:QUIC将加密和传输握手合二为一。通常,建立一个新的QUIC连接只需要1次往返(甚至0-RTT),而TCP+TLS需要2-3次往返。这意味着首次打开网页或重连时速度更快。
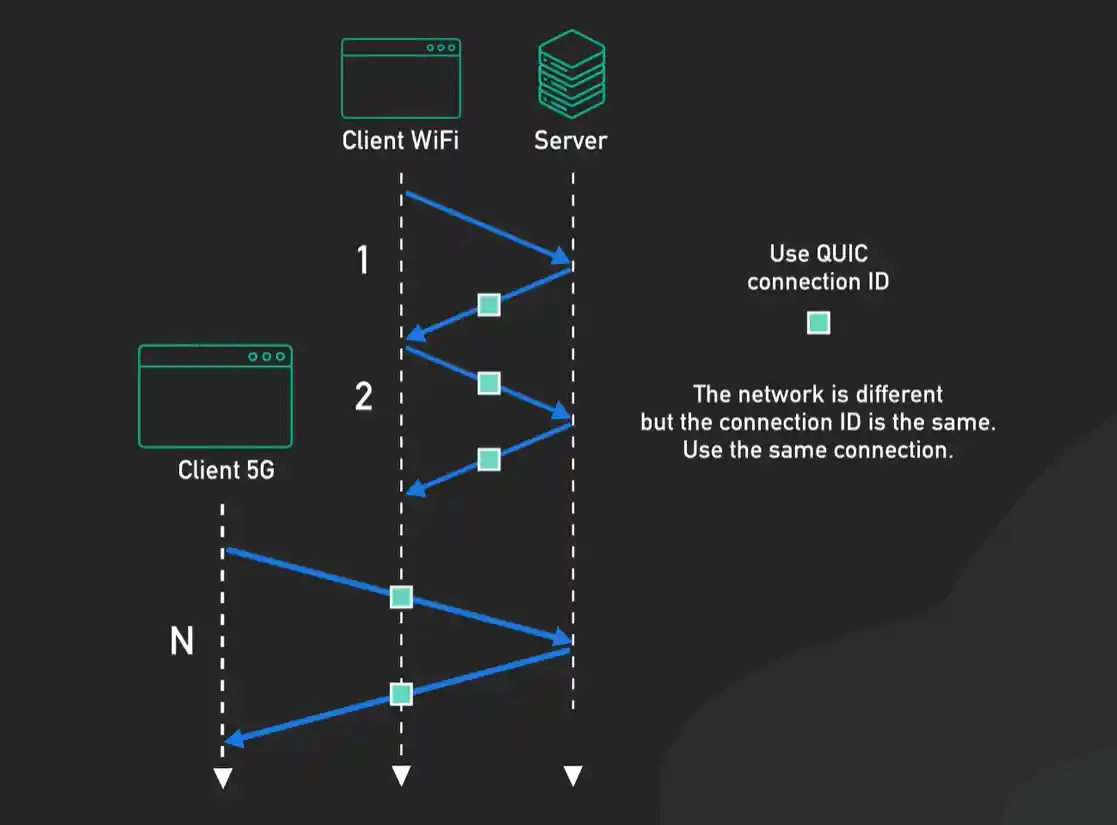
- 连接迁移:QUIC的连接不再用IP地址和端口号这种“物理标识”来绑定,而是用一个唯一的连接ID。当你从WiFi切换到4G网络(IP地址变了),你的QUIC连接可以无缝迁移,不断开,而TCP连接必然会中断重连。
所以,HTTP/3的出现,标志着优化重点从“应用层”下沉到了“传输层”。它不再接受TCP协议的历史包袱,而是为了现代网络的需求(特别是移动和实时性要求),重新设计了一套更灵活的传输基础。这当然带来了兼容性和部署复杂性的挑战,但其带来的性能潜力是巨大的。从HTTP/1到HTTP/2是“协议本身的现代化”,而从HTTP/2到HTTP/3,则是“传输基础的现代化”。
第2章:协议栈的接力——探索传输层与网络层的协作
本章核心:操作系统的协议栈如何接手应用层的请求,并为其准备踏上旅程?
- 传输层的使命:可靠 vs. 高效:为什么需要 TCP 和 UDP?面对“可靠传输”的根本需求,TCP 如何通过三次握手、序列号、确认应答、滑动窗口来构建一个虚拟的可靠通道?而 UDP 又为何选择“简单交付”?
- 网络层的使命:全局寻址:IP 协议如何为每个数据包赋予源和目标地址,使其具备在全局网络中穿行的身份?子网掩码与 CIDR 如何高效地划分和标识网络?
- 协议栈的内部协作:数据如何从应用层流下,被 TCP/UDP 封装,再被 IP 封装?端口号、IP 地址各自在哪一层起作用?
面试题逻辑起点:本章将剖析 TCP/IP 核心协议的设计哲学,解释连接状态、流量控制、拥塞避免及 IP 寻址背后的“为什么”。
第3章:数据包的本地旅程——探索网络设备与数据链路层
本章核心:封装好的 IP 数据包,如何离开你的主机,穿越本地网络?
- MAC 地址与 ARP 协议:在本地以太网中,设备间实际依靠 MAC 地址通信。如何通过 ARP 协议,根据下一跳的 IP 地址查询出其 MAC 地址?
- 交换机与二层转发:交换机如何根据 MAC 地址表,在数据链路层智能地转发帧,而非简单广播?它与集线器的本质区别是什么?
- 默认网关与路由器:当目标 IP 不在本地网络时,数据包如何被发送至默认网关(路由器)?这是网络层与链路层协作的关键一跳。
面试题逻辑起点:本章将澄清局域网通信的基础,重点区分 MAC 与 IP 地址的用途,以及交换机、路由器的核心工作原理。
第4章:穿越互联网边界——探索接入网与广域网路由
本章核心:你的数据包如何冲出“小家园”,融入全球互联网的“大江湖”?
- 接入网技术:数据包如何通过 ADSL、光纤、移动网络等“最后一公里”技术,离开你的家庭或办公网络,抵达你的互联网服务提供商?
- NAT 地址转换:为何你的私有 IP 能访问公网?路由器如何通过 NAT 将内网多个设备的流量映射为一个公网 IP,并管理回程连接?这如何影响了端到端通信?
- 核心路由协议 BGP:在 ISP 之间,数据包如何被引导穿越复杂的骨干网?BGP 作为“互联网的 glue”,如何基于策略和路径属性在不同自治系统间传递路由信息?
面试题逻辑起点:本章解释内网与外网的连通性奥秘,以及 NAT 和 BGP 这两个支撑现代互联网运转的关键技术。
第5章:服务器端的网络迷宫——探索数据中心架构
本章核心:数据包历尽千辛万苦抵达目标机房,迎接它的不是一台服务器,而是一个复杂的防御与调度系统。
- 防火墙与安全边界:如何通过 ACL、状态检测等技术,在第一道防线过滤恶意流量?
- 负载均衡器:面对海量请求,如何通过四层(L4)或七层(L7)负载均衡,将流量合理地分发到后方多台服务器集群?会话保持如何实现?
- 反向代理与缓存:像 Nginx 这样的反向代理,如何代表后端服务器处理连接、卸载 SSL、提供静态缓存,提升整体性能与安全?
面试题逻辑起点:本章揭示高并发、高可用服务背后的网络架构思想,理解流量治理和安全防护的常见手段。
第6章:请求的终结与新生——探索Web服务器的处理与响应
本章核心:数据包终于抵达目标 Web 服务器,它的使命结束了吗?不,这是一个新循环的开始。
- 服务器的处理流程:Web 服务器(如 Nginx/Apache)如何解包 HTTP 请求,根据虚拟主机配置将请求派发给对应的应用(如 PHP, Python 应用)?应用如何生成动态内容?
- HTTP 响应的生成:服务器如何构建状态码、响应头(如 Content-Type, Set-Cookie)和响应体,并将其封装回传?
- 响应的归途与浏览器渲染:响应数据如何沿原路径或新路径返回?浏览器如何接收响应、解析 HTML、加载 CSS/JavaScript、渲染 DOM 树,最终呈现出完整页面?
面试题逻辑起点:本章完成请求-响应的闭环,从服务端处理逻辑延伸到前端性能优化(如关键渲染路径),建立端到端的完整视角。